
“We are surrounded by data, but starved for insights”
JAY BAER
With respect to the quote above, it is absolutely critical to understand a significant problem that is making it challenging to deliver insights at lightning speed. The problem? Centralized data architecture.
Data is undoubtedly “ubiquitous” in nature. An outcome of every action we execute over the web is data. While technology makes it easy to collect this enormous and diverse data, the devil is found when it comes to processing and analyzing it using a centralized data architecture.
So what’s wrong with centralized data architecture? What’s the solution? In this blog, we will explore the answers to these questions.
Let’s get started 🚀
The centralized and monolithic approach compels the users to transport the data from edge locations to a central data lake so that it can be queried for analytics. This consumes a lot of time and is expensive in nature. A big hurdle to making the data readily accessible. So, if a time-sensitive decision needs to be implemented, this can create a problem.
When the volume of data continues to surge, the query method employed under the centralized model needs to experience changes in the entire data pipeline. Result? A reduced response time. When the total number of data sources increases, it becomes difficult to respond timely to new customers or data sources which severely affects the business dexterity.
The cross-border movement of data is subject to legal guidelines and privacy policies that are compulsory to be fulfilled before a migration is observed, making it difficult to deliver the data at speed. For example, a request from the user in the U.S to access the data stored in a European country cannot be completed before abiding by the data governance regulations and guidelines.
This not only kills a lot of time but the delay in delivering the data often puts the businesses in a less competitive spot.
Introducing the Solution: Data Mesh.
Before we make a straight dive into how Data Mesh rescues the day, let’s start with the basics first: What is Data Mesh?
A modern and distributed architecture that is decentralized and directly connects the data producers and data consumers with each other. No intermediary. No legal interference. No need to move the data to a data warehouse first.
A cluster of independent domains that are responsible to store, manage, and maintain the data.
The direct interaction model makes the data readily accessible and available creating a superlative experience for all the parties involved in the data transaction.
The idea of Data Mesh was first introduced by Zhamak Dehghani from Thoughtworks, Inc. Let’s have a look at the definition of Data Mesh from Thoughtworks itself:
“Data mesh is a decentralized sociotechnical approach to remove the dichotomy of analytical data and business operation. Its objective is to embed sharing and using analytical data into each operational business domain and close the gap between the operational and analytical planes. It’s founded on four principles: domain data ownership, data as a product, self-serve data platform, and computational federated governance.“
Furthermore, if you will have a look at the high-level diagram of the data mesh architecture (as explained by Zhamak Dehghani), you will observe how it allows the teams to have independent and autonomous ownership of their microservices. The information system is divided into distributed services that work in different domains.
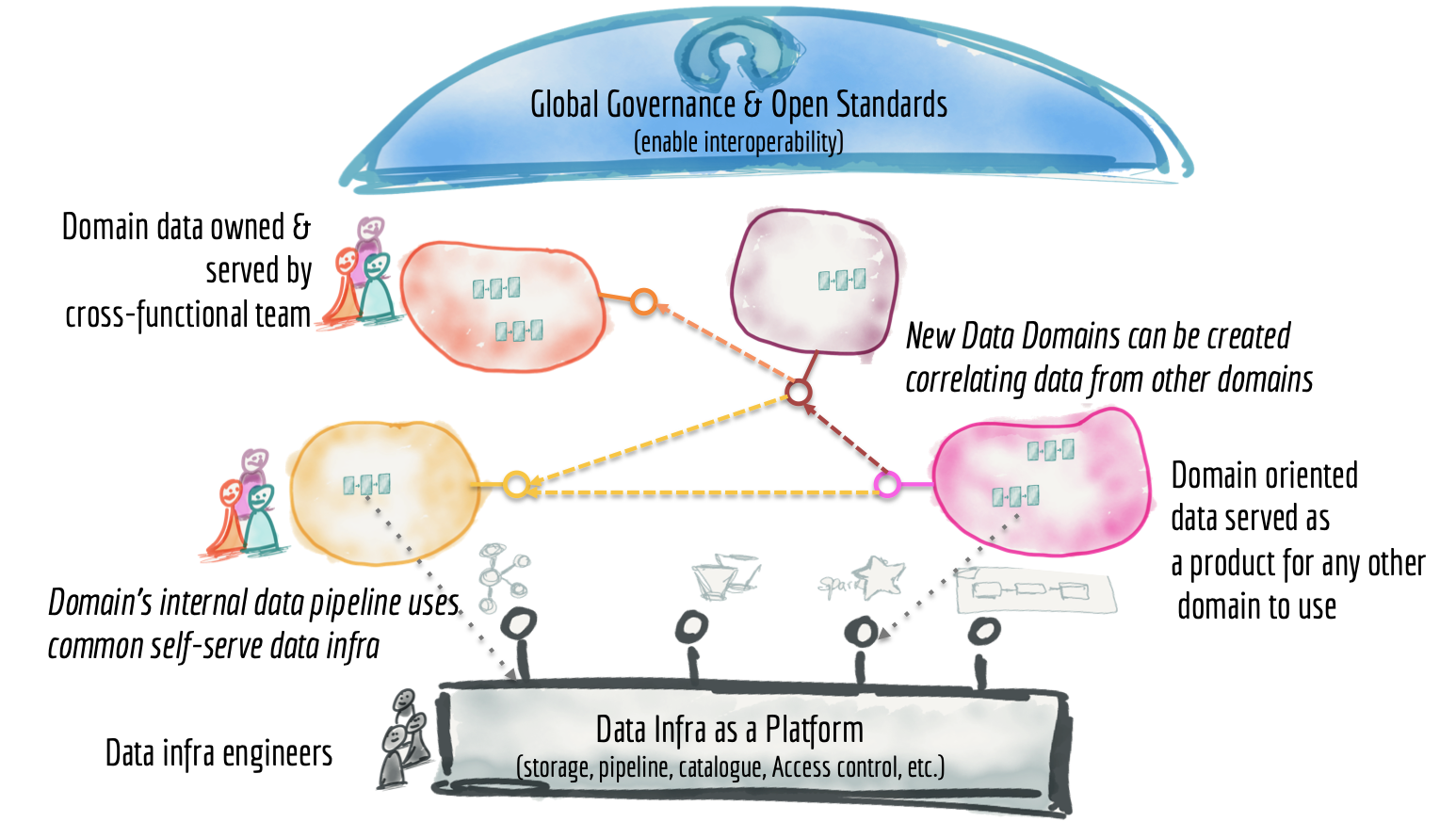
The solution to all the three problems found in a centralized data architecture (as discussed above) is Data Mesh. Owing to its decentralized infrastructure, the data is understood as a product having separate domain ownership. This allows eradicating the core problems that the centralized model is entangled with.
For more understanding, let’s have a closer look at the table illustrated below:
| PROBLEMS | DATA MESH SOLUTION |
|---|---|
| Time Consuming | The separate domain ownership (decentralization) enables a peer-to-peer interaction that significantly reduces the time consumed to access the data and generate insights. |
| Changes in the Entire Data Pipeline | The delegation of the data ownership to the individual teams allows business dexterity. Real-time decision-making is made possible by reducing the time gap between the execution of an event and its consumption. |
| Slow Cross-Border Movement of Data | The decentralized architecture of the Data Mesh makes only the domains responsible for the security and movement of the data. A connectivity layer is provided that allows directly accessing the data irrespective of location or residency. |
The findings from the aforesaid table make it evident that Data Mesh is a robust approach to having faster access to data insights. Although speed is not the only byproduct of this decentralized architecture. It brings many other benefits:
☑️ Rock Solid Data Security
☑️ Flexibility and Independence
☑️ Business Domain Agility
☑️ Robust Data Governance
As the human race is making rapid progress in this technology era, the need for analyzing and processing the data at a lightning speed has never been more important. The companies are pouring heavy investments to construct a robust data architecture that can effortlessly help in faster data processing in a secure environment.
However, most of these investments are made into a centralized approach where the data is kept in a single central repository which invites a lot of problems resulting in poor data quality. The best bet, in this case, is Data Mesh, a decentralized data architecture that removes the barriers for faster movement of data while also enabling flexibility, robust data governance, security, and much more.